前言
有熟人在开网店,了解到开网店就避免不了…你懂的
少量刷的时候还好,可等到大量刷就需要自己从别处一个个copy评论
看他每次copy得那么费劲,我就寻思自己能不能整个爬虫帮帮他
然后发现两个for循环就能搞定
那废话不多说,我们开始吧~
分析网页
参考连接:https://item.jd.com/10020746259899.html#crumb-wrap
因为我刚买了iPhone11,现在正缺手机壳,所以就以11的手机壳为例~
F12打开开发者工具先分析一波
具体怎么分析……就是找!挨着找!使劲找评论对应的json代码包!
然后终于在一个叫【productPageComments.action】的包中找到了
进【Preview】里瞅瞅是不是找对了
ok,评论藏在了【comments】下,被定义为【content】
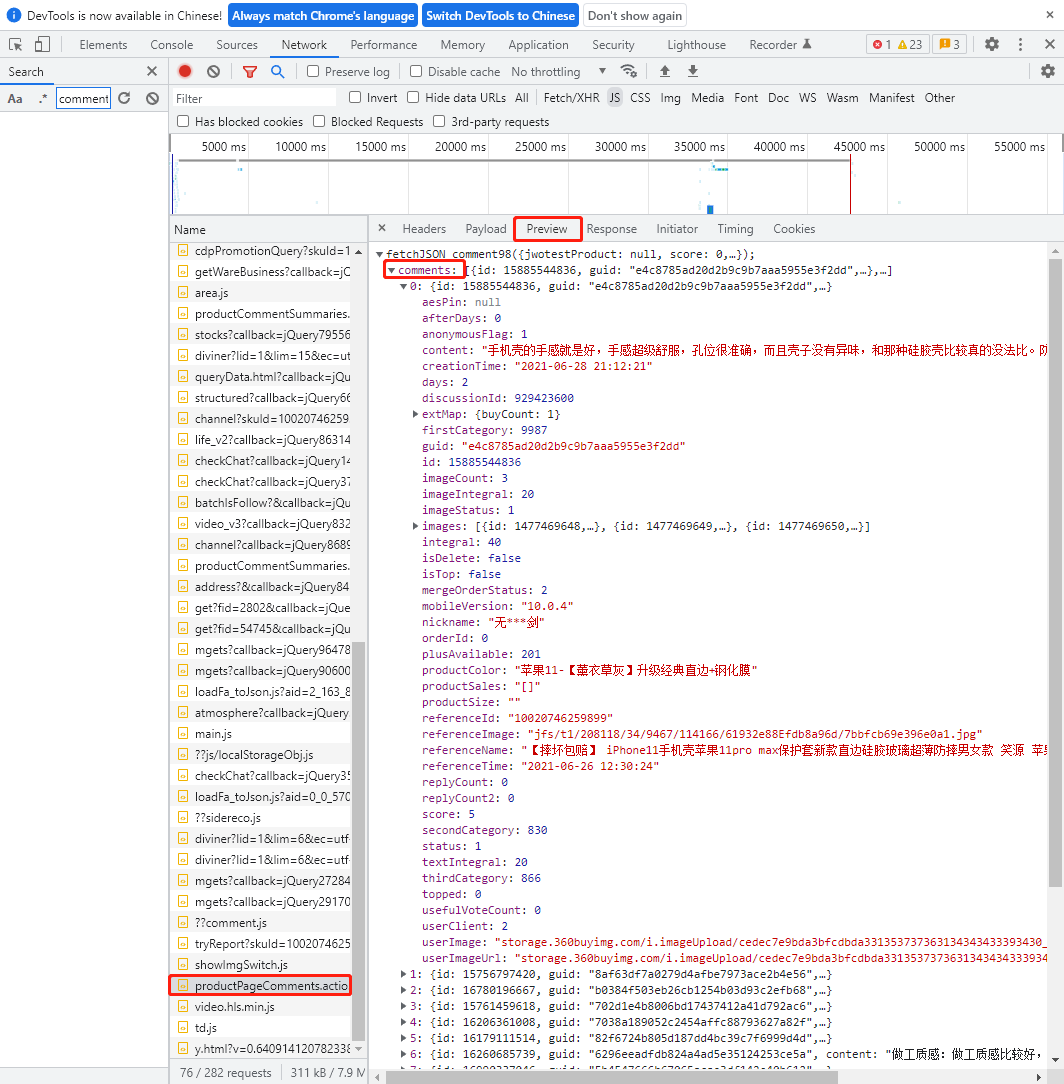
获取Request URL
通过这一步得到【productPageComments.action】的文本数据
好了,该得到的信息我们都得到了,然后我们上代码吧~
需要这几个module
import requests
import json
for循环①
用for循环的意义在于,每页就10条评论,如果只爬10条评论的话,不如直接手动copy
所以我把RequestURL拆分开了
把【页数】定义成了变量
这样用for循环的时候,就可以根据你设定的范围去获取更多页的评论了
for i in range(0,10):
url1 = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=10020746259899&score=0&sortType=5&page='
url2 = str(i)
url3 = '&pageSize=10&isShadowSku=0&fold=1'
finalUrl = url1+url2+url3
res = requests.get(finalUrl)
data = json.loads(res.text[20:-2])
for循环②
这个for循环是嵌套进for循环①里的
目的是为了遍历获取到json文本里我们需要的那部分信息
我们需要的就只有评论,而评论被定义为【content】
所以我们最终要得到的是它
为了方便检验是否有正确获取到,整个print输出监控下
然后因为如果直接把评论输出到控制台的话也不利于我们copy和查看
所以就需要将获取到的评论保存到本地
保存完毕后同样print输出一下方便自己监控进度
for i in data['comments']:
content = i['content']
print("已获取该条评论内容")
file = open("E:\\webcrawler\\comment.txt",'a')
file.writelines(format(content))
print("!完成写入!")



